Recently I’ve been seeing a resurgence of staffers at legacy data protection vendors quoting huge deduplication ratios on LinkedIn posts. Over the years I’ve seen 30:1, 100:1, even 155:1. The below post comes in at a magic 55:1 with “my 55:1 dedupe is better than vendor x 3:1 to 12:1 dedupe”.

What’s not being said is they are comparing logical deduplication to actual deduplication and how this logical ratio is being calculated. Why do this? Because it implies they are better with “numbers” and this chart of deduplication ratios would seem to back this claim:

However, the problem with logical deduplication ratios is that in a forever incremental backup world, where you only ever take 1 full backup and only changes thereafter, it is completely illogical. In fact, it’s bullshit. Why? Let me explain..
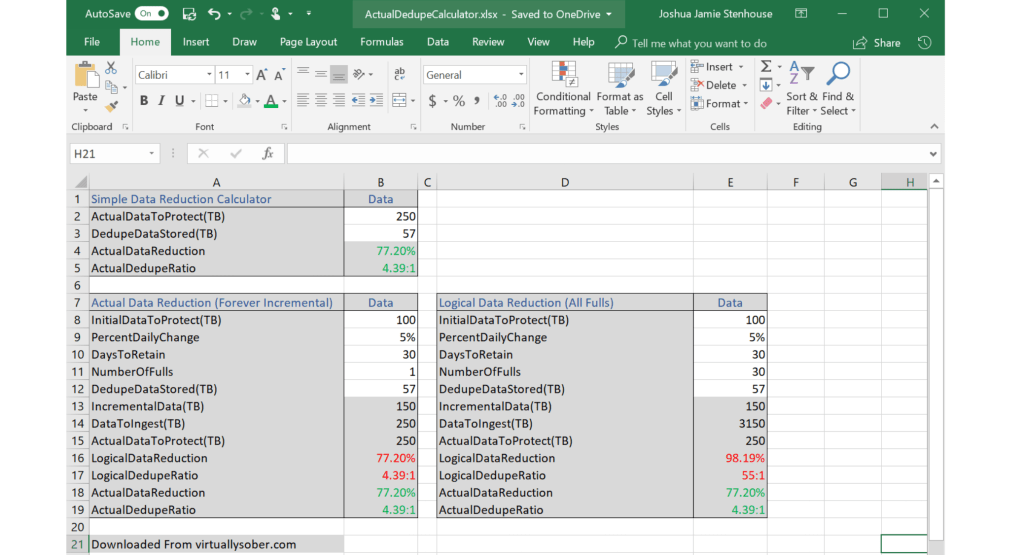
In a typical legacy backup environment, you take a weekly full and then daily incremental backups of only the changed data and retain them locally for 30 days. Maybe you’ve already switched to incremental forever. But irrespective of method, logical data reduction is unbelievably calculated as though a full backup is being taken, transferred, and deduped every day, plus the daily change:
(Full Backup x Days Retention) + (Daily Change x Days Retention) = Total Data Protected / Deduplicated Data Stored = Logical Deduplication Ratio
I.E (100TB VM Full Backup x 30) + (5TB Change Per Day x 30) = 3,150TB / 57TB Stored = 55:1
For Virtual Machines (VMs) worst case you are doing a weekly full, but many customers have already switched to incremental forever. So how can you calculate and compare dedupe based on data that isn’t even being sent? The simple answer is you can’t, hence it’s bullshit. The actual deduplication ratio should be calculated and compared using:
Total Full Backups + (Daily Change x Days Retention) = Total Data Protected / Deduplicated Data Stored = Actual Deduplication Ratio
I.E 1 x 100TB VM Full Backup + (5TB Change Per Day x 30) = 250TB / 57TB Stored = 4.39:1
So, in my example is your 55:1 logical dedupe better than my 4.39:1 actual dedupe as suggested in the LinkedIn post? No, both solutions are using 57TB of deduplicated storage. But it is a valid sales tactic to avoid talking about the real problems in infrastructure like cost, complexity, recovery, leveraging automation, cloud, and self-service.
Next time you see a post or hear this kind of claim, call them out! To help you calculate your own actual deduplication rates, and cut out the logical crap, I’ve created a simple excel spreadsheet below:
At this point, a vendor might say “ahhh, but Joshua, you seem to be talking about VMs where forever incremental is easy. What about NAS, Oracle and SQL data where I send a full backup every night?”. If your current backup solution or chosen methodology can’t or isn’t doing incremental forever, then it’s time to ditch it and modernize.
There’s simply no need to do error-prone, bandwidth hogging, time-sapping, heavy lifting of constant full backups for SQL, Oracle, NAS or VMs anymore! And irrespective of method, the most important figure is always how much deduplication storage is required not the mythical logical dedupe ratio.
Agree with me? Disagree? Feel free to leave a comment and discuss. Hope you enjoyed this post,
Joshua





Leave a comment