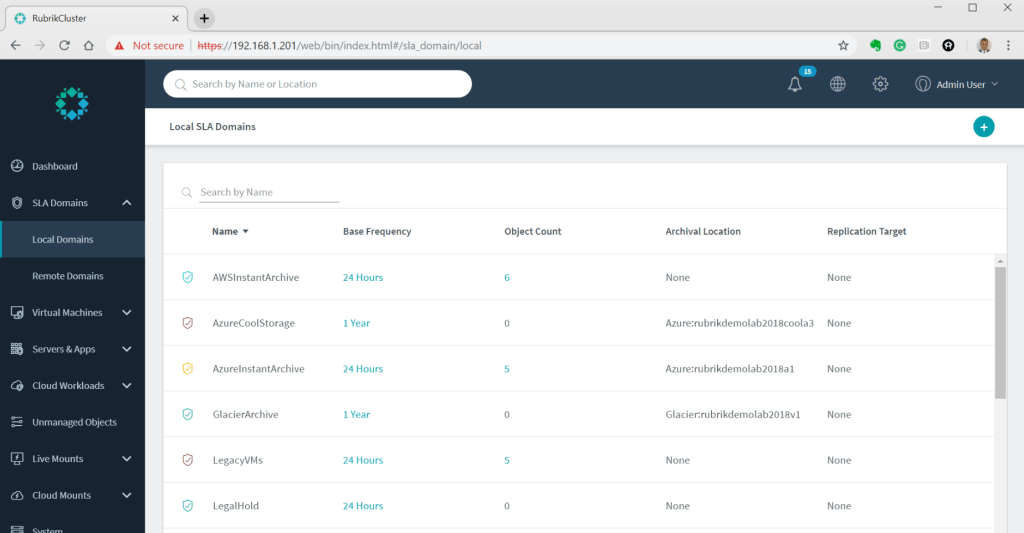
One of the most misunderstood and powerful features in Rubrik is the concept of the SLA Domain. It controls everything from the frequency to backup windows, retention, replication (to another Rubrik cluster), archiving (to S3/NFS/Object etc), and it also acts as the policy to determine compliance. In Rubrik you don’t have the complexity of creating and managing jobs, that’s a manual headache of legacy backup. Even vendors with competing modern scale-out technologies still require you to schedule jobs for everything. Their policy isn’t managing the backups for you, it’s merely for reporting/alerting. Essentially, it’s a fake Rubrik SLA Domain!
With Rubrik SLA Domains your scheduling is automatically managed and load balanced. Need to backup 1,000 VMs every night starting 9pm finishing 4am? Perfect! Assign the VMs to 1 SLA domain and at 9pm Rubrik will create 1,000 backup tasks in a pool, each Rubrik node takes 5 tasks while never running more than 3 VM backups per ESXi host. As each node completes a job it takes another from the pool. The net result is self-managing backups, no babysitting, no scheduling complexity, and why Rubrik just works!
But! “That’s great for 95% of my workloads” I hear you say, “what about the 5% where VM X or DB X needs to run at X, or as part of a workflow?”. Competitors would have you believe this isn’t possible, but it’s not true at all. Rubrik has 2 solutions for you.
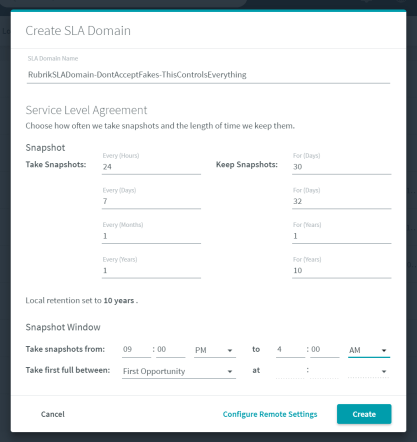
Solution 1. For backups that need to occur at a specific time, you simply need to create 1 SLA domain per object with the snapshot window at the start time you require. Yes, that’s it. To demonstrate I created 5 SLA Domains with backups starting at 8:15pm, with each SLA staggered 5 minutes behind the last. For the last 2 I set both to 8:30pm to demonstrate starting 2 backups simultaneously: We don’t need to worry about the end of the snapshot window as that merely controls the last time a job can start, and it especially doesn’t matter if you only have 1 object assigned as its going to run first. I then assigned the 5 SLA Domains to 5 different VMs, which should give me the following backup times:
We don’t need to worry about the end of the snapshot window as that merely controls the last time a job can start, and it especially doesn’t matter if you only have 1 object assigned as its going to run first. I then assigned the 5 SLA Domains to 5 different VMs, which should give me the following backup times:
DemoApp1-VM01 assigned to ScheduledJob1 8:15pm
DemoApp1-VM02 assigned to ScheduledJob2 8:20pm
DemoApp1-VM03 assigned to ScheduledJob3 8:25pm
DemoApp1-VM04 assigned to ScheduledJob4 8:30pm
DemoApp1-VM05 assigned to ScheduledJob5 8:30pm If you wanted to put the start time in your naming convention that might be a good idea, I.E “Job1-939pm-VMx”. I just called mine “ScheduledJobx-ObjectName”. With the SLAs created and objects assigned its time to sit back, crack open a beer, and watch the backups kick off. Right on time, like any backup system should, I saw the backups for each VM start, complete, and here you can see the result:
If you wanted to put the start time in your naming convention that might be a good idea, I.E “Job1-939pm-VMx”. I just called mine “ScheduledJobx-ObjectName”. With the SLAs created and objects assigned its time to sit back, crack open a beer, and watch the backups kick off. Right on time, like any backup system should, I saw the backups for each VM start, complete, and here you can see the result: Voila! Scheduled Rubrik backups, eat that Rubrik competitors! You can have the future while catering to the past. That was just VMs though, what about that critical SQL DB? I created a 6th SLA domain for SQL configured to backup at 10pm:
Voila! Scheduled Rubrik backups, eat that Rubrik competitors! You can have the future while catering to the past. That was just VMs though, what about that critical SQL DB? I created a 6th SLA domain for SQL configured to backup at 10pm: When assigning an SLA domain to a SQL DB we get the extra option of configuring log backups, which I set to every 15 minutes:
When assigning an SLA domain to a SQL DB we get the extra option of configuring log backups, which I set to every 15 minutes: Sure enough, I get a SQL full backup at 10pm:
Sure enough, I get a SQL full backup at 10pm: With backup scheduling out of the way the final thing to cover is running backups from a script as part of a workflow. As you can probably already guess I’m going to give you an example written in PowerShell. But for the first time on my blog, I’m going to use the fancy Rubrik PowerShell module.
With backup scheduling out of the way the final thing to cover is running backups from a script as part of a workflow. As you can probably already guess I’m going to give you an example written in PowerShell. But for the first time on my blog, I’m going to use the fancy Rubrik PowerShell module.
Now that you can download it from the PowerShell gallery with Install-Module (PowerShell 5.1 and above, please don’t run scripts on anything below this and ask for help!) it’s the simplest way to do it. Yes, I could show you all the API calls under the covers, but simplicity is the most important thing for this script and post.
Solution 2, to trigger a full backup all you need to run is this (example provided is for a SQL DB):
# Configure the below variables for your environment
$RubrikCluster = "192.168.1.201"
$SQLDBName = "SQL16-VM10-DemoDB03"
$SLADomainName = "Tier1-Gold"
# Running the script, nothing to change below
# Prompting for Rubrik Username and password
$RubrikCreds = Get-Credential
# Installing Rubrik module if not already installed
$RubrikModuleCheck = Get-Module -ListAvailable Rubrik
IF ($RubrikModuleCheck -eq $null)
{
Install-Module -Name Rubrik -Scope CurrentUser -Confirm:$false
}
# Importing Rubrik Module
Import-Module Rubrik
# Connect to Rubrik using module
Connect-Rubrik -Server $RubrikCluster -Credential $RubrikCreds
# Selecting DB ID
$SQLDBID = Get-RubrikDatabase | Where-Object {$_.name -eq $SQLDBName} | Select -ExpandProperty id
# POSTing request to Snapshot SQL DB
$SQLJobRequest = New-RubrikSnapshot -id $SQLDBID -SLA $SLADomainName -Confirm:$false
That’s nice and easy, but I mentioned this might be part of a process. What if you need to check the status of the task before performing another step? In my example, I assign the output of the backup request to a $SQLJobRequest variable and that’s for good reason. Simply add the next lines of script and you have a loop until the backup job has finished:
# Getting Status URL
$SQLJobStatusURL = $SQLJobRequest.links.href
# Setting counter
$SQLJobStatusCount = 0
DO
{
$SQLJobStatusCount ++
# Getting status
Try
{
$SQLJobStatusResponse = Invoke-RestMethod -Uri $SQLJobStatusURL -Headers $Global:rubrikconnection.header
# Setting status
$SQLJobStatus = $SQLJobStatusResponse.status
}
Catch
{
$_.Exception.ToString()
$Error[0] | Format-List -Force
$SQLJobStatus = "FAILED"
}
# Output to host
"SQLJobStatus: $SQLJobStatus"
# Waiting 15 seconds before trying again, but only if not succeeded
IF ($SQLJobStatus -ne "SUCCEEDED")
{
sleep 15
}
# Will run until it succeeds, fails, or hits 24 hours
} Until (($SQLJobStatus -eq "SUCCEEDED") -OR ($SQLJobStatus -eq "FAILED") -OR ($SQLJobStatusCount -eq 5760))
# Perform any next actions you want here
IF ($SQLJobStatus -eq "SUCCEEDED")
{
# Put your next script here
}
You can download this example and others (including individual VM and all VMs in an SLA) below:
RubrikOnDemandSnapshotPSModulev1.zip
If you enjoyed this post follow me on twitter using the link below,





Leave a comment